

بموازاة التقدم المتسارع في قدرات أنظمة الذكاء الاصطناعي التوليدية، خرجت تقنية التزييف العميق (Deepfake) من أوساط المختبرات ومجموعات القرصنة؛ لتتوافر كتطبيقات تجارية ومجانية تتيح لأي مستخدم توليد صور وفيديوهات وأصوات مصطنعة بواقعية عالية خلال دقائق، ومن دون حاجة إلى خبرة تقنية معمقة. وتحول هذا الانتشار إلى تهديد سيبراني عابر للقطاعات؛ من سرقة الهوية والاحتيال المالي، إلى التضليل الإعلامي وتشويه السمعة المؤسسية، وامتداد الأثر إلى الاستقرار السياسي والعلاقات الدولية.
محلياً في المملكة العربية السعودية، طرحت الهيئة السعودية للبيانات والذكاء الاصطناعي (سدايا) مبادئ وإرشادات للتزييف العميق بغرض المشاورة العامة وتعزيز موثوقية المحتوى والحد من إساءة الاستخدام ضمن الأطر التنظيمية الوطنية، وهو توجه هام ويتلاءم مع الحاجة المؤسسية للتحقق قبل النشر.
التزييف العميق بين سهولة الوصول وصعوبة الاكتشاف
يتأكد ذلك الاتساع بمؤشرات موثقة ومدروسة؛ إذ يثبت تقرير صادر عن Entrust في 2025 أن محاولة تزييف عميق وقعت كل خمس دقائق في عام 2024، مع زيادة سنوية قدرها 244% في تزوير المستندات الرقمية. كما تظهر تقارير Resemble AI أن الخسائر المالية الناتجة عن الهجمات القائمة على التزييف العميق تجاوزت 200 مليون دولار في الربع الأول من 2025 وحده، ما يشير إلى كلفة اقتصادية متصاعدة لهذا النمط من الاحتيال.
وإلى جانب ذلك، توثق دراسة محكمة في مؤتمر FAccT 2025 بعنوان Deepfakes on Demand وجود ما يقارب 35 ألف نموذج تزييف عميق متاح للتنزيل العام منذ نوفمبر 2022، مع قرابة 15 مليون تنزيل، وهو ما يبرز سهولة الوصول واتساع رقعة الاستخدام، ويعني عملياً أن عمليات التوليد المسيء باتت ممكنة على حواسيب استهلاكية وخلال فترات زمنية قصيرة.
حوادث تنذر بالأسوأ، وعلى أصعدة عدة
ولأن السياقات التطبيقية تجسد الخطر بوضوح، تبرز حوادث موثقة حديثة؛ فعلى مستوى الشركات، خسرت مجموعة هندسية عالمية تعمل في هونغ كونغ نحو 25 مليون دولار بعد أن تمكن مجرمون من استنساخ مظهر وصوت مسؤولين في اجتماع فيديو جماعي لإقناع موظف بتحويل الأموال وهي واحدة من أكبر عمليات الاحتيال المعتمدة على التزييف العميق حتى الآن.
وعلى نحو مشابه في السابق، نستذكر واقعة 2019 لانتحال صوت الرئيس التنفيذي لشركة طاقة بريطانية عبر تقليد صوتي عميق أدى إلى تحويل 220 ألف يورو بصورة احتيالية. وفي السياق الانتخابي بالولايات المتحدة، استخدم مجهولون مكالمات آلية بصوت مولد يحاكي صوت الرئيس الأمريكي السابق، جو بايدن، لحث ناخبين في نيوهامشير على عدم التصويت قبيل الانتخابات التمهيدية؛ وكنتيجة لذلك، قررت لجنة الاتصالات الفيدرالية الأميركية (FCC) اعتبار الأصوات المولدة بالذكاء الاصطناعي في المكالمات الآلية (Robocalls) مخالفة للقانون ما لم تحصل على موافقة صريحة مسبقة من المتلقي، مع اتخاذ إجراءات إنفاذ لاحقة في قضايا بارزة.
وعلى مستوى استغلال الصورة والشهرة، نبه ممثلون عالميون، وفي طليعتهم توم هانكس، جمهورهم إلى إعلانات مزيفة يجري فيها استعمال صورهم المولدة بالذكاء الاصطناعي دون إذن، بما يبين خطر إساءة استخدام الهوية البصرية في السوق الإعلاني.
على صعيد محلي، وضمن حملات رفع الوعي بمخاطر الاحتيال التقني، أصدرت لجنة الإعلام والتوعية المصرفية في البنوك السعودية تحذيراً رسمياً بخصوص انتحال الصفة والتضليل المرئي والسمعي ضمن حملاتها مكافحة الاحتيال أواخر 2024، وقد شهد الربع الأول من العام ذاته قفزة 600% في محاولات التزييف العميق بالمملكة، وفق شركة تحقق الهوية Sumsub.
الساحة العربية عموماً كانت مسرحاً لعدد من الحوادث المماثلة البارزة، ومنها ما نجم عنه تحويلات مالية احتالية بعد عملية استنساخ صوتي لإحدى الشخصيات، واختراق منصات إعلامية لبث دعاية سياسية في الإمارات العربية المتحدة. فضلاً عن وقائع أخرى في كل من مصر والأردن كذلك.
لماذا تعجز العين البشرية والتقنيات الحالية عن اكتشاف التزييف العميق؟
مع تطور تقنيات التزييف العميق، أصبحت الصور والفيديوهات المولدة أكثر واقعية من أي وقت مضى، وتحاكي الخصائص البصرية والسلوكية بدقة عالية، بحيث لا تظهر التشوهات السطحية التي اعتدناها في النماذج الأقدم، لاعتمادها على خوارزميات الشبكة التنازلية (GANs) التي تولد ملامح الوجه والإضاءة وحتى حركة العينين بطريقة تحاكي الطبيعة البشرية بدقة شبه مثالية. لهذا السبب، تفشل العين البشرية في التمييز بين المحتوى الحقيقي والمزيف، خاصة عندما يعرض ضمن سياق مألوف أو جودة عالية.
في السياق ذاته، أظهرت دراسات حديثة أن قدرة الإنسان على تمييز واكتشاف التزييف العميق لا تتجاوز غالباً مستوى قريباً من المصادفة؛ إذ سجلت تجارب منضبطة معدلات دقة تراوحت حوالي 60–64% عند الحكم على وجوه مولدة (StyleGAN2). وعلى مجموعة ArEnAV العربية-الإنجليزية، والتي تتضمن بيانات سمعية وبصرية للتزييف العميق ومنها تنويعات لهجات خليجية ومصرية، وشامية، سجل البشر دقة لا تتجاوز 60% في كشف التزييف. كما خلصت مراجعات ومنهجيات تجميعية حديثة (2024) إلى أن الأداء البشري يتذبذب حول هذا النطاق مع تباين حسب نوع الوسيط وجودته والسياق المعروض.
أما على المستوى التقني، فقد اعتمدت معظم أدوات الكشف المبكرة على شبكات التفافية (CNNs) مثل ResNet وVGG وDenseNet، مدربة على قواعد بيانات محددة، ورغم نجاح هذه النماذج في اكتشاف التزييف ضمن بيئات محددة أو عند تدريبها على بيانات معروفة، برزت مشكلة ضعف التعميم (Generalization) عبر المجموعات والخوارزميات، حيث يهبط الأداء بوضوح عند اختبارها على توليفات غير مرئية أو مجموعات خارج نطاق التدريب (cross-dataset)، ويرجع هذا الضعف إلى طبيعة عمل الشبكات الالتفافية نفسها؛ فهي تركز على الخصائص والدلائل المحلية منخفضة المستوى (ملمس البشرة، وحدود المزج، وآثار إعادة التشكيل، أو أنماط ترددية أخرى) دون أن تفهم العلاقة البصرية بين الأجزاء المختلفة من الصورة. وبالتالي، عند مواجهة تزييف يعتمد على تغييرات دقيقة في توزيع الإضاءة أو تماثل الوجه، تفشل CNNs في اكتشاف التناقضات الدقيقة التي لا تظهر في المناطق الصغيرة المعزولة.
هذا الخلل وثقته أعمال بحثية تظهر أن العديد من الكواشف تتعلم اختصارات تعتمد على شوائب أو سمات مميزة لمولد بعينه، بدل سمات سببية أكثر عمومية، ما يفسر فجوة النقل (الانتقال من بيئة وبيانات تدرب عليها النموذج إلى بيئة وبيانات مختلفة يختبر عليها) بين مجموعات مثل FaceForensics++، Celeb-DF وDFDC.
يزداد التحدي مع انتقال التوليد من GANs إلى نماذج الانتشار (Diffusion)؛ فهذه الأخيرة تقلل “بصمات” التشويه التقليدية التي كانت تتركها عمليات الرفع وإعادة التشكيل في الموجات والترددات، وهي البصمات التي اعتادت الكواشف الكلاسيكية تعقبها. تظهر دراسات متخصصة أن الكواشف المدربة على بصمات GAN تفشل جزئياً أمام مخرجات الانتشار، وأن صور الانتشار تميل إلى غياب الأنماط الشبكية عالية التردد المعهودة، ما يجعل الكشف اعتماداً على “الآثار” أصعب بكثير.
للتقليل من قصور الاعتماد على السمات المحلية والآثار، اتجهت الأبحاث الحديثة إلى مسارات ثلاثة متكاملة:
- تحسين التعميم عبر تدريب يراعي اختلاف مصادر التزييف ويستهدف خصائص “غير متحيزة للمصدر (مثل التعلم في المجال الترددي والتخفيف من الانحياز الطيفي)، وهو ما حسن أداء بعض النماذج على بيانات غير مرئية مقارنة بخطوط الأساس التقليدية.
- بنى محسنة أو هجينة (CNN + Transformers/ViT) تستفيد من الترابطات العالمية عبر الانتباه الذاتي إلى جانب التفاصيل المحلية، ما يخفف اعتماد الكاشف على “حيل” بيانات بعينها ويرفع قابلية النقل.
- علامات فيسيولوجية: خصوصاً إشارات التخطيط الضوئي للدم (rPPG) التي ترصد التغيرات الدقيقة في لون الجلد المتزامنة مع نبض الدم؛ إذ يصعب على التزييف الحفاظ على نسقها المكاني الزماني الطبيعي في الفيديو. وقد تبنت منصات صناعية مثل Intel FakeCatcher هذا النهج في كشف المحتوى المزيف آنياً، كما أيدته دراسات أكاديمية بتتبع الارتباط بين خرائط PPG والبنية البصرية للإطار.
كيف يعمل نموذج ViT؟
في ظل هذا المشهد، تبرز الحاجة إلى حلول ذكاء اصطناعي مضاد (AI-for-AI)، قادرة على مواجهة التزييف العميق بنفس التقنية التي تولده. ويأتي نموذج محول الرؤية، Vision Transformer ، أو ViT اختصاراً، أحد أبرز الابتكارات الأكاديمية التي نجحت في تحقيق هذا التوازن، إذ يظهر دقة عالية في اكتشاف الصور المزيفة ضمن مجموعات بيانات متعددة مثل Kaggle وStyleGAN.
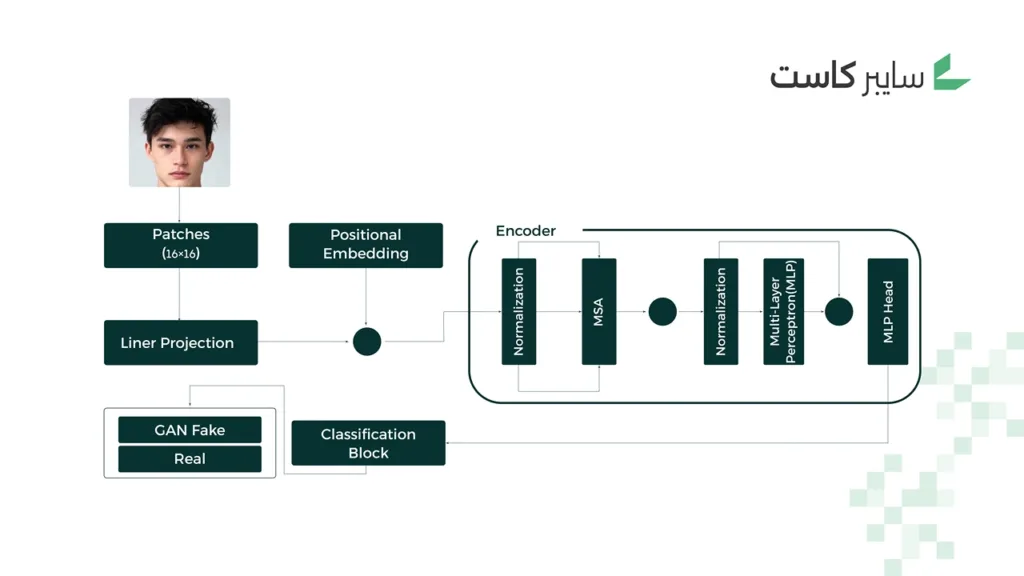
يقدم ViT مقاربة مختلفة جذرياً عن الشبكات الالتفافية؛ فهو:
- يقسم الصورة إلى أجزاء صغيرة (Patches)، ثم يتعلم العلاقات البصرية بينها باستخدام آلية الانتباه الذاتي المتعدد (Multi-Head Self-Attention)، وصولاً إلى تصنيف الصورة لجهة كونها حقيقية أو مزيفة.
- يركز على الخصائص العالمية (Global Features) بدلاً من الاقتصار على الملامح المحلية (Local Features)، ما يمكنه من التقاط فروقات دقيقة جداً في الإضاءة، والتناسق، والظلال يصعب على العين البشرية أو حتى شبكات CNN ملاحظتها. هذه القدرة على”رؤية الصورة كاملة” تجعل ViT أكثر مرونة عبر تقنيات توليد متنوعة، ومن بينها GANs ونماذج الانتشار (Diffusion) التي تظهر دراسات مختصة أنها تترك آثاراً رقمية أقل نمطية (خصوصاً في الترددات)، ما يصعب الاعتماد على بصمات تقليدية ويبرر تفضيل السمات العالمية.
توصيات
إن مستقبل الأمن الرقمي يتعدى مجرد الحماية من الهجمات، ويتطلب القدرة المؤسسية على تمييز الحقيقة من الخداع في بيئة تتسارع فيها قدرات التوليد الاصطناعي. وقد أصبح استخدام الذكاء الاصطناعي لكشف الذكاء الاصطناعي أكثر من مجرد خيار تقني، وهو أقرب لكونه ضرورة وطنية لتعزيز الثقة الرقمية وحماية المجالين الإعلامي والاقتصادي. وانسجاماً مع اتجاهات الحوكمة في المملكة، فإن دمج نموذج ViT وأدوات الإثبات (provenance) ضمن سلسلة الضوابط التقنية والتنظيمية سيكون خطوة استراتيجية محورية للسنوات القادمة.
دمج تقنيات ViT في مراكز الأمن السيبراني والإعلام الرقمي
بناء منصات كشف هجينة تجمع بين ViT وملامح محلية وطيفية وإشارات rPPG للفيديو، مع خطوط تشغيل شبه فورية (near real-time) في غرف الأخبار ومراكز العمليات الأمنية (SOC). مع مراعاة دمج هذا ضمن ضوابط الامتثال الوطنية (NCA/ECC) وإدارة مخاطر الذكاء الاصطناعي وفق NIST AI RMF.
إنشاء قاعدة بيانات وطنية للوسائط المزيفة
تأسيس قاعدة خاضعة لإدارة مركزية (بإشراف سدايا والجهات المختصة) لتجميع عينات واقعية من المحتوى المزيف والأصلي في البيئة السعودية، مع بيانات وصفية غنية (طريقة التوليد، والمولد المستخدم، وظروف الضغط والنقل، واللغات واللهجات، والحقوق والموافقات) ونسخ “منظمة أخلاقياً” تراعي الخصوصية.
تطوير تشريعات وطنية لتنظيم التحقق من الوسائط الرقمية
سن متطلبات إثبات المصدر (Provenance) والوسم الإلزامي للمحتوى المولد والمعدل بالذكاء الاصطناعي في المواد الحساسة (الانتخابية، والصحية، والمالية، والأمنية)، والاشتراط على الجهات الحكومية والمؤسسات الإعلامية تشغيل أدوات تحقق معتمدة قبل النشر. مع تحديد الضوابط بالمواءمة مع مبادئ سدايا للتزييف العميق، ومع أطر حوكمة البيانات الوطنية (NDMO/SDAIA) ومعايير إدارة أخطار الذكاء الاصطناعي (NIST AI RMF)، على أن يتم إلزام المنصات بتبني معرفات أو علامات مائية خفية ومتماهية مع الوسيط حيثما أمكن، إلى جانب سياسات احتفاظ وأرشفة تتيح التحقيق الجنائي الرقمي لاحقاً.
إطلاق حملات توعية وطنية
حملات متعددة الشرائح، تراعي الجمهور العام، لإرشاده لكيفية التعرف على دلائل المحتوى المشكوك، والرجوع إلى إثبات المصدر عند توفره. وتضع القطاعين الإعلامي والمالي في الاعتبار، عبر بروتوكولات التحقق قبل النشر أو التحويل المالي، والتحقق من الهويات الصوتية والمرئية. وللمسؤولين التنفيذيين أيضاً من خلال تجسيد سيناريوهات محاكاة احتيال عبر مكالمات فيديو أو صوت مولدة.




